
Knowledge is power. Small businesses and startups have to adopt this mindset when it comes to their data, which they need to treat as a veritable treasure trove of knowledge waiting to be explored. That’s where data mining techniques come in.
Though smaller companies face challenges in using their data, they shouldn’t be deterred from using techniques that can help them gain insights from the untapped potential of their data.
Startups and small businesses need to be empowered to treat data as the valuable commodity that it is and create strategies that can turn raw information into valuable insights that fuel decision making, strategies, and growth.
Exploring what data has to offer happens through data mining, which is a process that extracts meaningful, usable data from more voluminous sets of raw data. By now everyone has likely heard of data mining, but different data mining techniques have a lot to offer startups.
Like larger businesses and enterprises, startups should focus on data mining techniques to build strategies for customer relations, professional contacts, and sales and marketing. Data mining also provides a means for startups to answer questions in a problem-solving way, gaining the ability to manage better and allocate resources, assess risks and opportunities, and prepare for upcoming challenges.
What Is Data Mining
Data mining techniques allow data patterns to be identified within the larger quantities of data using specific software and tools. And through this process, startups can discover insights and gain knowledge about customers and sales, and learn more about their data, and apply this insight into objectives that are geared towards customer experience development, sales and marketing, market strategies, and other aspects of decision making that all businesses face on a daily basis.
it's a way of leveraging raw data in a way that makes it purposeful and meaningful. Data mining features elements of data collection and warehousing, and data processing, using statistical and mathematical based processes and algorithms.

Before You Start Data Mining, Things You Should Know
Before small businesses and startups grab the reins of data mining, they need to ensure that they understand what’s involved and how to use data mining to achieve the best benefits for their business. Background knowledge about your market, competitors, and business is important, so you know what to target in your data mining strategies.
-
01
Analyze Competitors Know where you stand in your market and understand how your competitors are marketing products and services, and how they are appealing to your shared customer base.
-
02
Adopt a Unique Message Ensure that your business can provide a solution to customer problems and has a strong standpoint.
-
03
Be customer centric Today’s businesses need to provide a relevant customer experience that caters to what customer want and need based on their purchasing behaviors.
-
04
Develop a Plan Have a long-term strategy with business objectives that allows you to work towards an overall goal.
-
05
Embrace Technology Start implementing technologies that allow you to take advantage of data and analytics to be more efficient, productive, informed, and provide enhanced experiences to customers.
Data mining is sometimes referred to as Knowledge Discovery, and startups and smaller businesses need to be equipped with the right kinds of knowledge, derived from their data, to stay competitive and make sound analytical decisions that help their company flourish and grow.
Different data mining techniques can provide the answers to your most pressing business questions, whether it’s about marketing, sales, customer habits, market risks, financial opportunities, or predictions for future expenditures.
Types of Data Mining
There are four primary types of data mining techniques that the entire industry uses:
-
01No-CouplingData Mining
-
02Loose CouplingData Mining
-
03Semi-Tight CouplingData Mining
-
04Tight CouplingData Mining
01
No-Coupling Data Mining
This is best for very simplified data mining processes and doesn’t rely on functionality from either databases or data warehouse systems.
The Architecture of No-coupling Data Mining
This architecture doesn’t utilize features or functionality offered by the database or data warehouse system, and retrieves data from a specific source and processes it through different algorithms to locate patterns and store results in a file system.
Data Mining Process for No-coupling Data Mining
This technique collects data from a specific source and uses an appropriate algorithm to process that data.
Data Mining Techniques for No-coupling Data Mining
No integration to a database or data warehouse. Flat file processing is not recommended when using a database or data warehouse system.
Advantages and Disadvantages of No-coupling Data Mining
Advantages include using significant data mining algorithms and being able to store results in the file system.
The disadvantage is that it doesn’t use the database or data warehouse that is already effective for organizing, storing, and retrieving data. it's also considered a relatively weak data mining architecture.
Association in No-coupling Data Mining
Association rules can be produced that show attribute-value circumstances that often occur together in any given data set.
Classification in No-coupling Data Mining
Uses sources like flat files to gather initial data sets for mining because data warehouse and database system functions aren’t implemented as part of the procedure, so this architecture sometimes represents a weak design scheme.

Case Study – No-coupling Data Mining
This technique was used to improve patient-centered mobile apps for health management. The purpose was to use results for patient follow-up and monitoring, early diagnostics, and risk calculation, and understand how to better address patients needs. This study also wanted to investigate how data mining techniques helped the self-management components of healthcare apps regarding accuracy and reliability.
Thirty different research articles were produced that broke down the data mining methods for patient self-management through the app. Thirteen of the studies found an accuracy level of 90% or higher, and seven of the research studies reported over 95% accuracy about data mining algorithm performance.
The data mining techniques addressed capabilities like prediction, estimation, and detection for every individual patient while gathering his/her data. These results help in the ongoing development of mobile apps that can produce new methods of providing health care to those living with chronic conditions.
02
Loose Coupling Data Mining
This data mining format collects any segment of data within a database with a lot of agility and efficiency.
The architecture of Loose Coupling Data Mining
This data mining system retrieves data from within a database and stores results and is a memory based system.
Process for Loose Coupling Data Mining
This system uses some functions of DB and DW systems gathering data from a repository and conducting data mining and storing the outcomes in a file, database, or data warehouse.
Techniques of Loose Coupling Data Mining
This system draws on both database and data warehouse functions to gather data from the repository and conduct data mining on that data. The outcome is stored in a file, data warehouse, or database.
Advantages and Disadvantages of Loose Coupling Data Mining
The benefits include real-time data and low latency, increased agility, and affordability because data localization isn’t necessary.
Disadvantages include potential issues with semantics within the schema and a less speedy query response because of unlocalized data, as well as a dependency on the data sources.
Association in Loose Coupling Data Mining
Association rules should be generated that semantic display values in the query inputs that are taken from the source database to combined with outcome sets.
Classification in Loose Coupling Data Mining
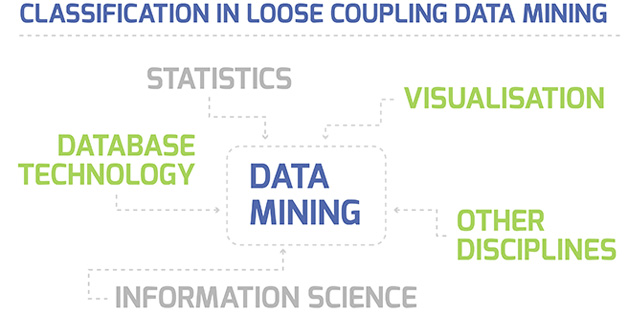
This makes the data mining system able to be classified by the types of mined databases, the kind of mined knowledge, and the methods or the applications that have been utilized.

Case Study – Loose Coupling Data Mining
This technique was used to execute two models in different logistic clusters for workflow dependency and schedule in the Telco industry. Customers were segmented into multiple clusters where similar behaviors were grouped, and class data was processed through filtering 39 columns and 300 million rows of raw data into 20 columns that included customer attributes, service charges, communication, and message information.
The company was able to obtain an 89% accuracy level compared to the actual result, and the telco operator was able to improve experiences for customers.
03
Semi-Tight Coupling Data Mining
You may want to specify some background information or domain knowledge in the area of data that's going to be mined because this can help with the knowledge discovery process and identification of patterns within data, and it can help guide the process.
The Architecture of Semi-Tight Coupling Data Mining
This system utilizes different data lakes or data warehouse system components for data mining activities like indexing, sorting, and aggregation, and certain results can be stored in a database or data warehouse for improved performance.
The Process of Semi-Tight Coupling Data Mining
This process links the data mining system to a data warehouse or database, and some data primitives can be applied to the database.
Techniques of Semi-Tight Coupling Data Mining
This system can be connected to a data warehouse system where some data mining primitives can be applied in the relational database/data warehouse system. Data primitives can include indexing, sorting, histogram, aggregation, and pre-computation of different statistical methods.
Advantages and Disadvantages of Semi-Tight Coupling Data Mining
Advantages include being able to link to a database or warehouse system, utilizing different features of data warehouse and database systems for data mining methods like sorting or indexing. Also, results can be stored in a database or data warehouse for better performance.
Association in Semi-Tight Coupling Data Mining
Measures for association rules include supportive elements, such as the percentage of the data mining task for which the rule pattern appears, and confidence in the gauged strength of rule implication.
Classification in Semi-Tight Coupling Data Mining
The classification in data mining of this architecture includes relational database functions and subclasses determined by attributes and mind patterns.

Case Study – Semi-Tight Coupling Data Mining
This technique was applied in a healthcare case study to assess how impatient visits affected Medicare and Medicaid patients by region, including average length of visit and associated financial impact. Patient demographics were factored into the analysis, and the reports were used to understand better how age affected care and financial loss per institution.
04
Tight Coupling Data Mining
First, the source data must be retrieved by computing queries and generating a view of the source that contains the data that will be processed. And then the number of groups within the source data needs to be accounted for.

The Architecture of Tight Coupling Data Mining
This architecture consists of 3 levels:
-
01
Data Layer Acts as an interface for different data sources and the mined results can be stored within this layer.
-
02
Data mining application This layer retrieves data from a database and transformation tasks are performed here to alter the data into the necessary format whereby the data is processed using appropriate data mining algorithms.
-
03
Front-end layer Provides an intuitive interface for users that facilitates interaction with the system and results can be visualized in a format in the front end layer.
The Process of Tight Coupling Data Mining
Here the database or data warehouse acts as an information retrieval feature for data mining using integration and performs data mining activities. The architecture offers scalability, increased performance, and integrated data.
Techniques for Tight Coupling Data Mining
Seamless integration of the data mining system into the data warehouse or database occurs in this technique. The subsystem acts as a single element of an information system.
Advantages and Disadvantages of Tight Coupling Data Mining
Advantages include a decreased dependency to source systems because the data is copied over, speedy and complex query processing, advanced storage capabilities and sophisticated data summarization and capable of processing voluminous data.
Disadvantages include latency issues due to the data having to be loaded using ETL, and this is usually a more expensive technique because of the infrastructure requirements, security, and data localization.
Association in Tight Coupling Data Mining
The three-step process is used to integrate into a tight coupling and the association and classification function into a relational database.
Classification in Tight Coupling Data Mining
Functions into a relational database. The uniformity of the processing environment for this architecture classifies sub-systems of an individual functional element and classifies query analysis by data structures, indexing schemas, and differing query processing.
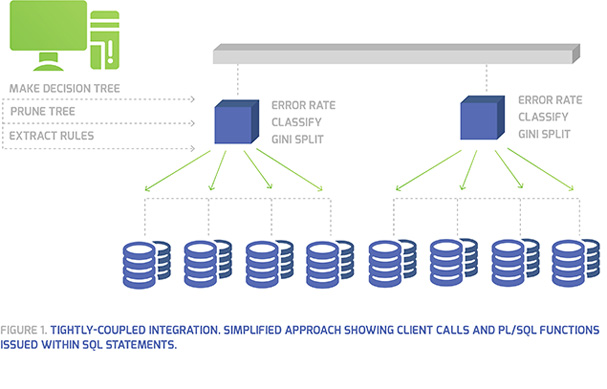
Tightly Coupled Integration for Case Study
Case Study – Tight Coupling Data Mining
This data mining technique was used for a life insurance system that featured data about customers insurance contracts and insurance taxes. The database was primarily used in a data warehousing environment, and the objective was to classify customers based on all the data. Demographic information about customers including date of birth, career, gender, marital status, etc., was organized and a database was created to maintain information about insurance tax prices associated with each customers insurance contract.
How to Use Data Validation and Data Enrichment
Data validation: Data validation determines how your data mining models are performing compared to real data. Mining models need to be validated to assess quality and characteristics before applying them in a production environment.
Data mining measures reside in 3 categories:
 Dependant on the type of data being used. Values may be missing or approximate, or the data might have been altered during processing. During exploratory and developmental phases, a certain degree of error within data is ok, particularly if the data is pretty standard in characteristics. A model that forecasts sales for a business using historical sales data could be extremely accurate even if the store used incorrect accounting methods for example.
Dependant on the type of data being used. Values may be missing or approximate, or the data might have been altered during processing. During exploratory and developmental phases, a certain degree of error within data is ok, particularly if the data is pretty standard in characteristics. A model that forecasts sales for a business using historical sales data could be extremely accurate even if the store used incorrect accounting methods for example. Determines how a data mining model performs with varying sets of data and is reliable if similar predictions or uniform patterns are generated no matter the kind of tech data that is provided. The model that is created for the retail store that used inaccurate accounting methods would not generalize well with other stores for example, and thus, it isn’t reliable.
Determines how a data mining model performs with varying sets of data and is reliable if similar predictions or uniform patterns are generated no matter the kind of tech data that is provided. The model that is created for the retail store that used inaccurate accounting methods would not generalize well with other stores for example, and thus, it isn’t reliable. Includes different metrics that determine if the model offers useful data. A data mining model that connects a stores location with sales figures might be accurate and reliable but not particularly useful because results can’t be standardized, by adding more stores at the same location, for example. This also doesn't answer an important business question of why a specific location might have better sales.
Includes different metrics that determine if the model offers useful data. A data mining model that connects a stores location with sales figures might be accurate and reliable but not particularly useful because results can’t be standardized, by adding more stores at the same location, for example. This also doesn't answer an important business question of why a specific location might have better sales.
Validation Tools for Mining Models
Multiple approaches to validation of data mining that supports all stages of the testing processes include:
-
01Segmenting data into testing/training sets.
-
02Filtering models to train/test varying mixtures of the same source data.
-
03Evaluating lift and gain to visualize data mining model improvements.
-
04Cross-validation
-
05Creating classification matrices that sort accurate and inaccurate hypothesis into tables to facilitate faster evaluation of how the model predicts target values.
-
06Scatter plots to evaluate the regression formula fits.
-
07Profit charts to connect financial profits and expenditures with mining model usage so that the recommendation value can be determined.
There are six general components in data enrichment procedures:
-
01
Data Fusion
Integrates numerous data sets that represent the same real-world object in a precise and useful representation and enables information to be concentrated into a single area.
-
02
Named Entity Recognition
This procedure finds and identifies people, businesses, cities, or any type of predefined entity and the problem is typically modeled as a classification problem with sophisticated classifiers.
-
03
Data Disambiguation
Textual data is integrated from differing extraction systems, which necessitates disambiguation entity mentions within the text. This process is critical because of unstandardized variations in the entity names and can be modeled as a classification issue.
-
04
Segmentation
Groups of data are segmented depending on sets of required or predefined features and uses clustering data mining techniques to understand the data.
-
05
Data Imputation
Estimates values for missing and inconsistent data fields and should be used when data is intended for use for data characterization or model generation. After missing data values have been imputed, data sets can be analyzed with standard techniques.
-
06
Data Categorization
Data is manually or automatically labeled depending on the varying category types.
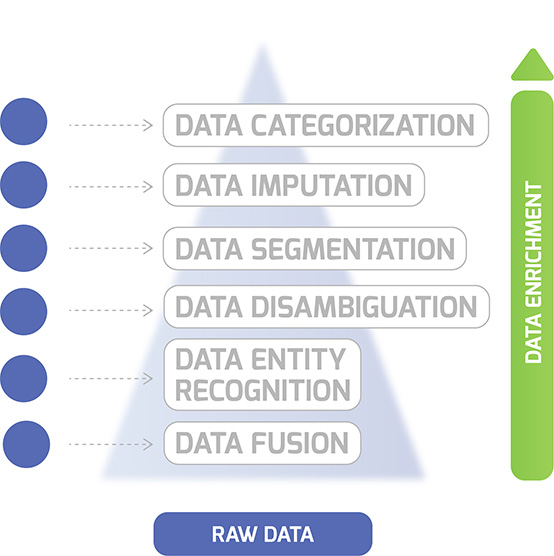
Components of the data enrichment process:
- Data enrichment activities must be reproducible.
- Data enrichment activities should have an evaluation guideline.
- Data enrichment activities need to be scalable.
- Data enrichment activities need to be complete regarding the input domain.
- The result of the data enrichment activity needs to be consistent with input and activity objectives.
- Data enrichment activities need to be cost-effective and apply to various data types and application synopsis.
Data Mining Dos:
- Ask the right questions to understand the problem.
- Develop a well-defined objective for data mining assignments and figure out how you can measure success.
- Prepare for messy data that call for time-consuming actions like extract, transform, and load time.
- Validate data after the ETL process against original values to discover any potential errors before mining or modeling occurs.
- Simplify solutions for improved rate of success and to reduce chances of overfitting models.
- Utilize multiple techniques and algorithms.
- Stay educated and informed on trending data mining techniques.
Data Mining don'ts:
- To evaluate appropriate data preparation processes such as data cleansing, transforming, and aggregating model input data.
- Utilize default model accuracy metrics.
- Overfit data instead use proper testing procedures like randomization tests to reduce the likelihood of identifying false patterns in the test data.
- Don’t rely entirely on algorithms or software.
- Don’t underestimate the power of domain knowledge for cross-checking the different variables.
- Underestimate more basic solutions that might be a little less accurate because your clients might not trust a complex model that they don’t understand.
Help Your Startup Stand Out with Professional Data Mining Services
Experts and business leaders agree that data mining generates value and knowledge to empower companies and transform their data into information that can be used for strategies and connecting business objectives with action.
“Small or mid-sized businesses don’t have to spend millions developing such systems. All you need is a spreadsheet and the willingness to enter your sales data on a regular basis.” -American Express.
“Larger companies have been mining huge data warehouses for decades… but thanks to lower technology costs and broader access to data, smaller companies can now get in on the act.” – Financial Post
“Defined goals make the task of mining big data more manageable because you can start with only the data that will support whatever strategy you intend to implement that tie in with the specific goal. – The Tech Republic.
“Data mining tools and techniques are now more important than ever for all businesses, big or small if they would like to leverage their existing data stores to make business decisions that will give them a competitive edge.” -Invensis Technologies
Data Entry Outsourced helps startups take advantage of all their data and use it for diverse business purposes by providing affordable, purposeful, and scalable data mining services for list building techniques and decision making. With a relevant, problem-solving approach to varying types of data mining processes, startups will be able to explore and develop uses for all of their data based on high quality and well-performing models and results.
– Data Entry Outsourced
Disclaimer:All the product names, logos, trademarks, and brand names are the property of their respective owners. All the products, services, and organization names mentioned in this page are for identification purpose only and do not imply endorsement.



