Automated or Manual Image Annotation to Build AI Models
The process of making the object of interest traceable and recognized to machines is known as image annotation. Image annotation has become a crucial aspect of AI development for creating machine learning training data and models.
It aids in the conversion of items into visuals that machines can recognize. And, as long as annotated images are available for training machines, prediction accuracy will be higher, allowing AI developers to create the best model.
Companies are actively employing the automatic approach to annotate the images by machines and get a large amount of data in the race to supply such training data.
Even though you can annotate a huge number of images in less time with automatic image annotation tools, it does not mean that they will solve your problem. There are numerous obstacles that customers experience when using automatic image annotation tools.
In this post, we will discuss the automatic and manual data annotation processes. We will also shed light on some key differences between automatic and manual annotation.
Automated Image Annotation
The process of a computer system automatically assigning metadata to a digital image in the form of labels or keywords is known as automatic image annotation. It is also known as automatic image labeling.

AI firms are trying to create the most accurate and high-performing Machine Learning model possible. But, the number of datasets is unimportant; rather, the game of locating and collecting the most edge-cases is crucial for training the AI model.
As a result, it's more vital for a corporation to throw aside the trivial pieces of data that AI models are already well-trained on. They must focus more time and effort on identifying high-value data intelligently. As a result, the AI-assisted data annotation process improves the capacity to produce accurate datasets, allowing AI to be used in a variety of new sectors.
Manual Image Annotation
The technique of manually selecting regions in an image and providing a written description of those parts is known as manual image annotation. For example, machine learning algorithms for computer vision applications can be trained using such annotations.
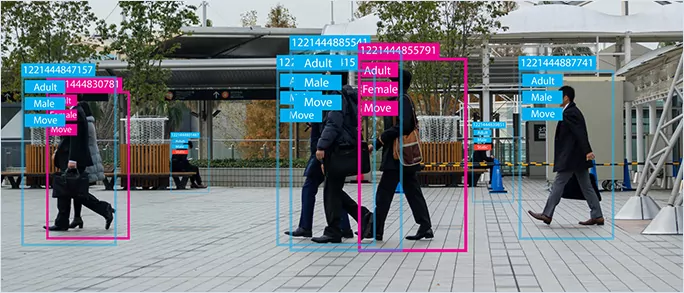
Annotators are given a batch of raw, unlabeled data, such as photographs or videos. They are given instructions on how to classify it using a set of rules or specialized data annotation methodologies.
Bounding box or polygon annotations are two of the simplest and least expensive annotation strategies, requiring less time and effort. In contrast, semantic segmentation necessitates more work and finer annotations. Objects are chosen from a list during the manual data annotation procedure.
Automated image annotation vs. Manual image annotation
Here we draw a comparison between automatic and manual image annotation.
| Attribute | Automatic | Manual |
| Time consumption | When compared to manual annotation, the data annotation and quality check procedure take less time with automated data annotation. | The data annotation and quality check procedures take a long time and require additional skills and effort to manually mark the items in the images. |
| Flexibility | If the images are present in the right format, automatic image annotation can be useful. But, the challenge is that any new project or image class needs software updations or adjustments in the annotation technique. | Manual or human-powered image annotation solves the flexibility issues because it can update the annotation if they find different classes of images and can react accordingly. |
| Unsupervised Learning Process | Unsupervised machine learning cannot use automatic image annotation because machines would struggle to find and identify the objects in images. | Manual image annotation works better with unsupervised machine learning because people can detect new objects and mark them so that machine learning models can recognize them. |
| Scalable Solution for Turnaround Demand | Large production demands in automatic image annotation can be impossible to meet. This is due to the fact that machines are designed or manufactured to generate a specific number of things. | The manual image annotation method can be scaled up to meet customer needs. Manual or Human-powered image annotation offers a scalable solution for fast turnaround times, allowing AI firms to get the training data they want. |
Conclusion
To annotate images, there are two technical approaches: automated data annotation and manual data annotation. Both approaches have their benefits and drawbacks.
Despite the fact that automated image annotation delivers a better output and that technological advancements bring more efficiency and quality, manual image annotation is necessary to assure quality and accuracy when labeling data for AI models.
So, to choose one, we must be astute in determining which method produces the highest-quality training datasets for Machine Learning.


